robots-txt
什麼是 robots.txt?

robots.txt 檔案是用於機器人的一組指令。此檔案包含在大多數網站的來源檔案中。robots.txt 檔案主要用於管理網路爬蟲等善意機器人的活動,因為惡意機器人不太可能遵循指令。
把 robots.txt 檔案想像成一個貼在健身房、酒吧或社群中心牆上的「行為準則」標誌:標誌本身無權執行列出的規則,但「有素質的」顧客會遵守規則,而「沒有素質的」顧客可能會違反規則並被驅逐。
機器人是與網站和應用程式互動的自動化電腦程式。有善意機器人和惡意機器人,其中一種善意機器人稱為網路爬蟲機器人。這些機器人「爬行」網頁並索引內容,以�便它可以顯示在搜尋引擎結果中。robots.txt 檔案有助於管理這些網路爬蟲的活動,以便它們不會使託管網站的網頁伺服器負擔過重或索引不適合公眾檢視的頁面。
robots.txt 檔案如何工作?
robots.txt 檔案只是一個沒有 HTML 標記代碼的文字檔案(因此副檔名為 .txt)。robots.txt 檔案託管在網頁伺服器上,就像網站上的任何其他檔案一樣。⭐️事實上,通常可以透過輸入首頁的完整 URL,然後新增 /robots.txt(如 https://www.cloudflare.com/robots.txt),來檢視任何給定網站的 robots.txt 檔案。該檔案未連結到網站上的其他任何地方,因此使用者不太可能偶然發現它,但大多數網路爬蟲機器人會先尋找此檔案,再爬行網站的其餘部分。
雖然 robots.txt 檔案為機器人提供了指令,但它實際上無法強制執行這些指令。網路爬蟲或新聞摘要機器人之類的善意機器人會先嘗試造訪 robots.txt 檔案,然後再檢視網域上的任何其他頁面,並按照指令進行操作。惡意機器人要麼會忽略 robots.txt 檔案,要麼會對其進行處理以找到被禁止的網頁。
網路爬蟲機器人將遵循 robots.txt 檔案中最具體的一組指令。如果檔案中存在相互矛盾的命令,機器人將遵循更精細的命令。
需要注意的一件重要事情是,所有子網域都需要自己的 robots.txt 檔案。例如,雖然 www.cloudflare.com 有自己的檔案,但所有 Cloudflare 子網(blog.cloudflare.com、community.cloudflare.com 等)也需要其自己的檔案。
robots.txt 檔案中使用什麼通訊協定?
在網路中,通訊協定是一種用於提供指令或命令的格式。robots.txt 檔案使用幾種不同的通訊協定。主要通訊協定稱為 Robots 排除通訊協定。這會告訴機器人要避免哪些網頁和資源。針對此通訊協定進行格式化的指令包含在robots.txt 檔案中。
用於 robots.txt 檔案的另一個通訊協定是網站地圖通訊協定。這可以被視為機器人包含通訊協定。網站地圖向網路爬蟲顯示他們可以爬行哪些網頁。這有助於確保網路爬蟲機器人不會錯過任何重要頁面。
robots.txt 檔案範例
以下是 www.cloudflare.com 的robots.txt 檔案:
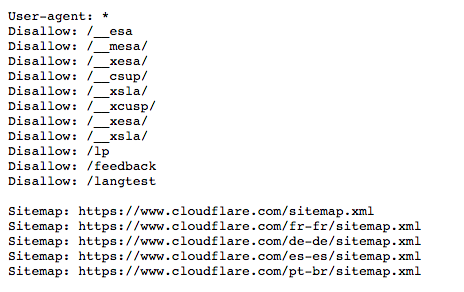
下面我們將分解其含義。
什麼是使用者代理程式?「User-agent: *」是什麼意思?
在網際網路上作用的任何人或程式都將有一個「使用者代理程式」,或者說指派的名稱。對於人類使用者,這包括瀏覽器類型和作業系統版本等資訊,但不包括個人資訊;它可以幫助網站顯示與使用者系統相容的內容。對於機器人,使用者代理程式(理論上)可以幫助網站管理員瞭解哪種機器人正在爬行網站。
在 robots.txt 檔案中,網站管理員能透過為機器人使用者代理程式編寫不同的指令來為特定機器人提供特定指令。例如,如果管理員希望某個頁面顯示在 Google 搜尋結果中而不顯示在 Bing 搜尋中,他們可以在 robots.txt 檔案中包含兩組命令:一組命令前面帶有「User-agent: Bingbot」,另一組前面帶有「User-agent: Googlebot」。
在上面的範例中,Cloudflare 在 robots.txt 檔案中包含了「User-agent: *」。星號表示「萬用字元」使用者代理程式,表示指令適用於每個機器人,而不是任何特定機器人。
常見的搜尋引擎機器人使用者代理程式名稱包括:
Google:
- Googlebot
- Googlebot-Image(用於影像)
- Googlebot-News(用於新聞)
- Googlebot-Video(用於影片)
Bing
- Bingbot
- MSNBot-Media(用於影像和影片)
百度
- Baiduspider
「Disallow」(不允許)命令在 robots.txt 檔案中是如何運作的?
Disallow 命令是 Robots 排除通訊協定中最常見的命令。它告訴機器人不要存取命令後面的單個或多個網頁。不允許的頁面不一定是「隱藏的」——它們只是對普通的 Google 或 Bing 使用者沒有用,所以不會顯示給他們看。大多數情況下,網站上的使用者如果知道在哪裡可以找到它們,則仍然可以導覽到這些頁面。
Disallow 命令可以透過多種方式使用,上面的範例中顯示了其中幾種方式。
封鎖一個檔案(或者說,一個特定的網頁)
例如,如果 Cloudflare 想要阻止機器人爬行我們的「什麼是機器人?」一文,則會編寫以下命令:
Disallow: /learning/bots/what-is-a-bot/
在「disallow」命令之後,會包含首頁後面的網頁 URL 部分,在本例中為「www.cloudflare.com」。使用此命令后,善意機器人將不會存取 https://www.cloudflare.com/learning/bots/what-is-a-bot/,而且該頁面也不會出現在搜尋引擎結果中。
封鎖一個目錄
有時,一次封鎖多個頁面比單獨列出所有頁面更有效。如果它們都在網站的同一區段,則 robots.txt 檔案可以封鎖包含它們的目錄。
延續上面的範例:
Disallow: /__mesa/
這意味著不應爬行 __mesa 目錄中包含的所有頁面。
允許完全存取
這樣的命令如下所示:
Disallow:
這告訴機器人它們可以瀏覽整個網站,因為沒有什麼是不允許的。
對機器人隱藏整個網站
Disallow: /
這裡的「/」表示網站階層中的「根」,或所有其他頁面從中分支出來的頁面,因此它包括首頁和從它連結的所有頁面。使用此命令,搜尋引擎機器人將根本無法爬行該網站。
換句話說,一根正斜線可以使整個網站在網際網路上無法搜尋!
Robots 排除通訊協定中還有哪些命令?
**Allow:**正如人們所期望的那樣,「Allow」命令告訴機器人它們被允許存取某個網頁或目錄。此命令允許機器人存取一個特定網頁,同時不允許存取檔案的其餘網頁。並非所有搜尋引擎都認可此命令。
**Crawl-delay:**crawl delay 命令旨在阻止搜尋引擎蜘蛛機器人使伺服器負擔過重。它允許管理員指定機器人每個請求應等待的時間(以毫秒為單位)。下面是等待 8 毫秒的 Crawl-delay 命令範例:
Crawl-delay: 8
Google 不認可此命令,但其他搜尋引擎認可。對於 Google,管理員可以在 Google Search Console 中變更其網站的爬行頻率。
什麼是網站地圖通訊協定?為什麼它包含在 robots.txt 中?
網站地圖通訊協定可幫助機器人瞭解在爬行網站時要包含哪些內容。
網站地圖�是一個 XML 檔案,如下所示:
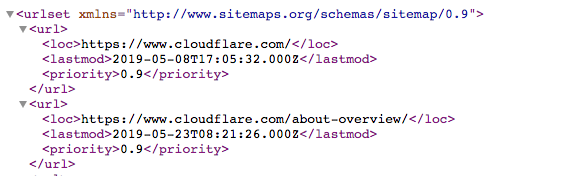
它是網站上所有頁面的機器可讀清單。透過網站地圖通訊協定,指向這些網站地圖的連結可以包含在 robots.txt 檔案中。格式為:「Sitemaps:」,後跟 XML 檔案的網址。您可以在上面的 Cloudflare robots.txt 檔案中看到幾個範例。
雖然網站地圖通訊協定有助於確保網路蜘蛛機器人在爬行網站時不會錯過任何內容,但機器人仍將遵循其一貫的爬行過程。網站地圖不會強制網路爬蟲機器人以不同的方式確定網頁的優先順序。
robots.txt 與機器人管理有何關係?
管理機器人對於保持網站或應用程式的正常執行至關重要,因為即使是善意機器人活動也會加重原始伺服器的負擔,從而導致 Web 資產速度減慢或無法存取。結構良好的 robots.txt 檔案可讓網站針對 SEO 進行最佳化,並且可控制善意機器人活動。
但是,robots.txt 檔案對管理惡意機器人流量沒有多大作用。Cloudflare 機器人管理或 Super Bot Fight Mode 之類的機器人管理解決方案,可在不影響網路爬蟲等必要機器人的情況下,遏制惡意機器人活動。
robots.txt 復活節彩蛋
有時,robots.txt 檔案會包含復活節彩蛋——開發人員包含的幽默訊息,因為他們知道使用者很少看到這些檔案。例如,YouTube robots.txt 檔案中寫道:「Created in the distant future (the year 2000) after the robotic uprising of the mid 90's which wiped out all humans.(在 90 年代中期機器人起義消滅了所有人類之後,在遙遠的未來(2000 年)建立。)」Cloudflare robots.txt 檔案則寫到,「Dear robot, be nice.(親愛的機器人,友好一點。)」
# .__________________________.
# | .___________________. |==|
# | | ................. | | |
# | | ::[ Dear robot ]: | | |
# | | ::::[ be nice ]:: | | |
# | | ::::::::::::::::: | | |
# | | ::::::::::::::::: | | |
# | | ::::::::::::::::: | | |
# | | ::::::::::::::::: | | ,|
# | !___________________! |(c|
# !_______________________!__!
# / \
# / [][][][][][][][][][][][][] \
# / [][][][][][][][][][][][][][] \
#( [][][][][____________][][][][] )
# \ ------------------------------ /
# \______________________________/
Google 還有一個「humans.txt」檔案,位於以下位置:https://www.google.com/humans.txt
https://www.cloudflare.com/zh-tw/learning/bots/what-is-robots-txt/